Données on-premise
Les données on-premise (aussi appelées données sur site ou en local) désignent les données stockées, traitées et gérées sur une infrastructure physique située dans les propres locaux d'une organisation, centres de données d'entreprise ou salles serveurs, plutôt que dans un environnement cloud tiers.
Les organisations qui gèrent des données on-premise possèdent et opèrent leur propre matériel, leurs licences logicielles et leur infrastructure réseau.
Bien que le cloud computing soit devenu le paradigme dominant de la gestion moderne des données, l’infrastructure on-premise reste prévalente, en particulier dans
- les secteurs fortement réglementés,
- les organisations soumises à des exigences spécifiques de souveraineté des données,
- les entreprises disposant d’investissements technologiques legacy, pas encore prêts pour la migration.
Caractéristiques clés des données on-premise
- Contrôle total : les organisations ont une propriété et un contrôle complets sur le matériel, les logiciels et les configurations de stockage des données, sans dépendance envers la disponibilité ou les politiques d’un fournisseur tiers.
- Souveraineté des données : les données restent dans une juridiction géographique définie, soutenant la conformité aux réglementations de localisation des données et aux exigences de cloud souverain.
- Modèle d’investissement en capital : l’infrastructure on-premise requiert un investissement initial matériel et des coûts de maintenance permanents, à l’opposé du modèle de dépenses opérationnelles du cloud.
- Contrôle du périmètre de sécurité : les périmètres de sécurité physique et les architectures réseau privées fournissent une couche d’isolation supplémentaire vis-à-vis des menaces externes.
On-premise vs. cloud vs. hybride
- On-premise : données et traitements restent entièrement dans l’infrastructure de l’organisation. Fort niveau de contrôle, charge de maintenance élevée.
- Cloud : données stockées et traitées sur l’infrastructure de fournisseurs (AWS, Azure, Google Cloud). Forte flexibilité, moindre charge opérationnelle.
- Hybride : combinaison d’environnements on-premise et cloud connectés pour permettre aux données de circuler entre eux, géré via des outils d’intégration des données et de pipeline de données.
Défis des environnements on-premise
Malgré leurs avantages, les données on-premise introduisent une complexité opérationnelle :
- Limitations de scalabilité : l’expansion de la capacité on-premise nécessite des cycles d’achat et des investissements en capital, à l’inverse de la mise à l’échelle élastique du cloud.
- Complexité d’intégration : connecter des systèmes on-premise aux outils data modernes, aux applications SaaS et aux pipelines de données requiert souvent des middlewares et une infrastructure ETL supplémentaires.
- Besoins en talents : maintenir une infrastructure on-premise nécessite des compétences IT et data engineering spécialisées, de plus en plus rares à mesure que l’expertise cloud domine le marché.
Les données on-premise dans le modern data stack
Pour de nombreuses entreprises, les données on-premise ne disparaissent pas, elles sont intégrées dans des architectures hybrides où les systèmes legacy coexistent avec des data warehouses cloud-native et des data marketplaces. Cela requiert des cadres de gouvernance des données robustes couvrant les deux environnements, garantissant la cohérence de la qualité des données, du data lineage et du contrôle d’accès, quelle que soit la localisation physique des données.
Pour en savoir, lire notre article : L’agilité du cloud pour votre data marketplace : égaler les standards de sécurité de l’on-premise
En savoir plus
La combinaison de Denodo et Huwise offre aux organisations une solution unique, alliant la flexibilité et la performance de la data virtualisation, avec la puissance du partage de données via des data product marketplaces pour garantir l'adoption et la consommation des données.
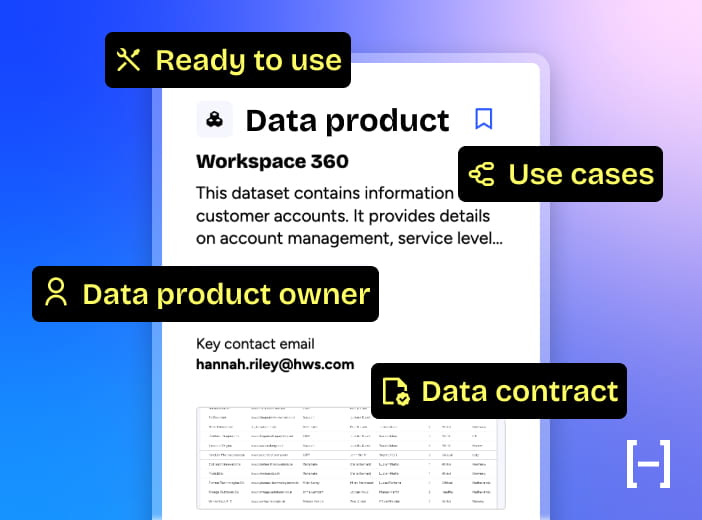
Un data product n'est pas un dataset de plus dans votre patrimoine data. C'est une donnée packagée, documentée, avec un owner identifié et des utilisateurs réels : pilotée comme un vrai produit. La différence ne tient pas à la donnée elle-même, mais aux engagements qui l'entourent pour garantir son usage. Voilà ce que ça change concrètement.

Comment la gestion des données et l'IA vont-elles évoluer à l'horizon 2030 ? Pour le savoir, nous avons interrogé l'expert de référence Michel Lutz Chief Data Officer et Digital Factory Head of Data & AI chez TotalEnergies, parrain de la communauté Data Voices 2026.
La combinaison de Denodo et Huwise offre aux organisations une solution unique, alliant la flexibilité et la performance de la data virtualisation, avec la puissance du partage de données via des data product marketplaces pour garantir l'adoption et la consommation des données.
Un data product n'est pas un dataset de plus dans votre patrimoine data. C'est une donnée packagée, documentée, avec un owner identifié et des utilisateurs réels : pilotée comme un vrai produit. La différence ne tient pas à la donnée elle-même, mais aux engagements qui l'entourent pour garantir son usage. Voilà ce que ça change concrètement.
Comment la gestion des données et l'IA vont-elles évoluer à l'horizon 2030 ? Pour le savoir, nous avons interrogé l'expert de référence Michel Lutz Chief Data Officer et Digital Factory Head of Data & AI chez TotalEnergies, parrain de la communauté Data Voices 2026.
