Data product autonome
Un data product autonome est un data product capable de gérer son propre cycle de vie : ingérer, traiter, valider, documenter et distribuer la données, avec peu ou pas d'intervention humaine.
Allant au-delà de la définition standard d’un data product en tant qu’actif data gouverné, réutilisable et hautement consommable, un data product autonome intègre l’intelligence, l’automatisation et les capacités d’auto-réparation (self-healing) nécessaires pour fonctionner de manière indépendante au sein d’une architecture plus large de data mesh ou de data marketplace.
Le concept se situe à l’intersection de l’approche data-as-a-product, des métadonnées actives (active metadata) et de l’automatisation pilotée par l’IA. Il représente le prochain niveau de maturité pour les organisations qui ont déjà établi de solides fondations en matière de data products.
Ce qui rend un data product « autonome »
Tous les data products ne se valent pas. L’autonomie existe sur un spectre, et un data product véritablement autonome présente plusieurs caractéristiques distinctives :
- Auto-descriptif : le data product met à jour en continu ses propres métadonnées, la documentation de son schéma, ses scores de qualité, ses indicateurs de fraîcheur et ses statistiques d’utilisation, sans intervention manuelle d’un data steward ou d’un data product owner.
- Auto-surveillé : l’observabilité intégrée détecte les anomalies de volume, de distribution et de dérive de schéma, déclenchant des alertes automatisées ou des flux de remédiation alignés sur les normes de qualité des données.
- Auto-réparateur : lorsque des problèmes de données en amont sont détectés, le data product peut tenter une correction automatisée, mettre en quarantaine les enregistrements suspects ou passer en mode dégradé, en informant les consommateurs de manière transparente plutôt que d’échouer silencieusement.
- En libre-service : le data product expose ses données via des APIs gouvernées ou des interfaces de requête auxquelles les consommateurs peuvent accéder directement, sans nécessiter l’intervention de l’équipe productrice, tenant ainsi la promesse de la données en libre-service.
- Auto-optimisé : le data product apprend des modèles d’utilisation, ajustant les stratégies de mise en cache, priorisant les dimensions fréquemment interrogées ou recommandant des actifs associés, s’améliorant ainsi au fil du temps sans réglage manuel.
Le rôle de l’IA et des métadonnées actives
Les data products autonomes sont propulsés par une combinaison de pipelines de métadonnées actives et d’orchestration pilotée par l’IA. Les flux de métadonnées actives envoient des signaux en temps réel, des modèles de requêtes, des changements de schéma et des défaillances en amont vers des couches d’automatisation qui déclenchent les réponses appropriées.
Des agents d’IA peuvent être déployés pour gérer des tâches spécifiques du cycle de vie :
- classer automatiquement de nouveaux champs de données,
- générer des descriptions en langage naturel,
- évaluer si une nouvelle version de la donnée respecte les obligations définies dans un contrat de données (data contract).
Les data products autonomes dans une data marketplace
Dans une data product marketplace, les data products autonomes réduisent considérablement la charge opérationnelle des producteurs et Data product Owner tout en augmentant la confiance des consommateurs.
Lorsqu’un data product peut certifier sa propre fraîcheur, documenter son propre lignage et informer proactivement les consommateurs des changements, la marketplace devient un écosystème vivant et de confiance, plutôt qu’un catalogue statique d’actifs nécessitant une curation manuelle constante.
Data products autonomes face aux data products standards
- Data product standard : gouverné, documenté et réutilisable, mais nécessite un effort humain pour maintenir la qualité, les métadonnées et la gestion du cycle de vie.
- Data product autonome : gouverné, documenté et réutilisable. Le data product gère activement sa propre santé, sa documentation et l’expérience consommateur grâce à une intelligence et une automatisation intégrées.
Les data products autonomes représentent la convergence de la gouvernance des données, du DataOps et de l’IA. Ils offrent une évolution naturelle pour les organisations qui font passer à l’échelle leurs stratégies de data products au-delà de ce que la seule curation humaine peut soutenir.
En savoir plus
La combinaison de Denodo et Huwise offre aux organisations une solution unique, alliant la flexibilité et la performance de la data virtualisation, avec la puissance du partage de données via des data product marketplaces pour garantir l'adoption et la consommation des données.
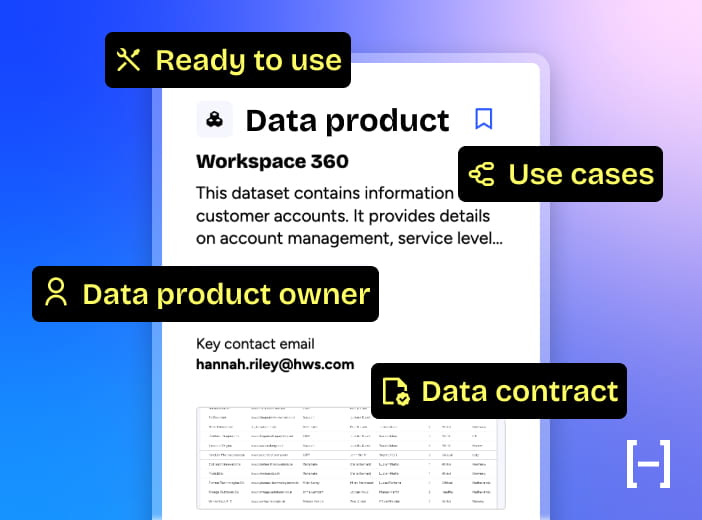
Un data product n'est pas un dataset de plus dans votre patrimoine data. C'est une donnée packagée, documentée, avec un owner identifié et des utilisateurs réels : pilotée comme un vrai produit. La différence ne tient pas à la donnée elle-même, mais aux engagements qui l'entourent pour garantir son usage. Voilà ce que ça change concrètement.

Comment la gestion des données et l'IA vont-elles évoluer à l'horizon 2030 ? Pour le savoir, nous avons interrogé l'expert de référence Michel Lutz Chief Data Officer et Digital Factory Head of Data & AI chez TotalEnergies, parrain de la communauté Data Voices 2026.
La combinaison de Denodo et Huwise offre aux organisations une solution unique, alliant la flexibilité et la performance de la data virtualisation, avec la puissance du partage de données via des data product marketplaces pour garantir l'adoption et la consommation des données.
Un data product n'est pas un dataset de plus dans votre patrimoine data. C'est une donnée packagée, documentée, avec un owner identifié et des utilisateurs réels : pilotée comme un vrai produit. La différence ne tient pas à la donnée elle-même, mais aux engagements qui l'entourent pour garantir son usage. Voilà ce que ça change concrètement.
Comment la gestion des données et l'IA vont-elles évoluer à l'horizon 2030 ? Pour le savoir, nous avons interrogé l'expert de référence Michel Lutz Chief Data Officer et Digital Factory Head of Data & AI chez TotalEnergies, parrain de la communauté Data Voices 2026.
