What is a data product? Definition, characteristics and practical implementation
A data product is not just another dataset in your data estate. It is packaged, documented data with an identified owner and an actual user community: managed as a real product. The difference lies not in the data itself, but in the commitments that surround it to guarantee its use. Here's what that means in practice.
There’s a lot of confusion around what a data product actually covers. Some call any CSV export a “data product”. Others see it as a complex architecture accessible only to technical teams. The truth is simpler but still demanding: a data product is not just another dataset in your data estate. It is packaged, documented data with a clear owner and defined users.

A data product in our organization is defined by an identified owner, a service contract (SLA) and full traceability. By structuring these internal assets we avoid calculation redundancies and poorly governed data, creating a pivot towards a genuine operational transformation.

What is a data product?
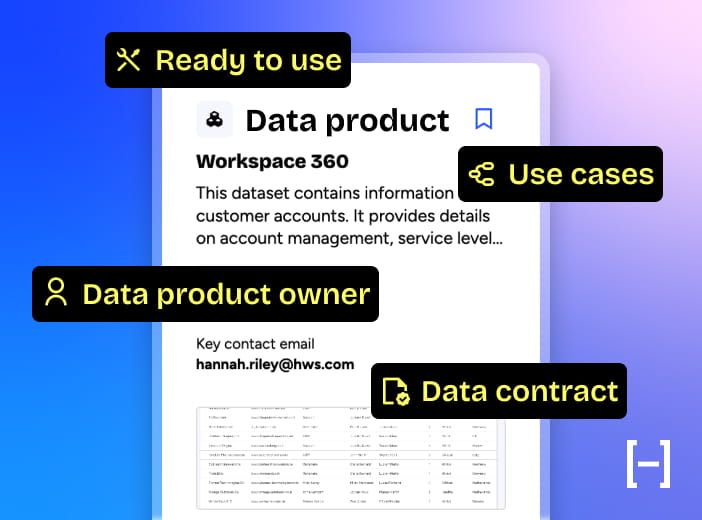
A data product is designed like a real product: documented, reliable, maintained over time, with an identified owner, a clear data contract and defined service commitments. Its objective is not only to make data available, but to make it immediately exploitable – including by non-technical profiles – through a smooth access experience and adapted consumption modes (prepared views, API, exports, etc.).
Like any product, it has a lifecycle, users, performance indicators and a team responsible for its evolution. But a dataset does not become a data product by simply changing its label: it becomes one when it addresses a concrete need, is actually consumed and delivers value to its users.
This approach is rooted in the Pareto principle: like on Netflix or Amazon, a minority of assets concentrates the majority of usage. In practice, 20% of data often generates 80% of the value. In most organisations, only a small portion of datasets is actually used, reused and integrated into business processes. These are the high-impact assets that become data products; the others remain available data, but rarely consumed.
What are the 5 essential characteristics of a data product?
Not all data earns the status of a data product. A true data product is distinguished by five key characteristics:
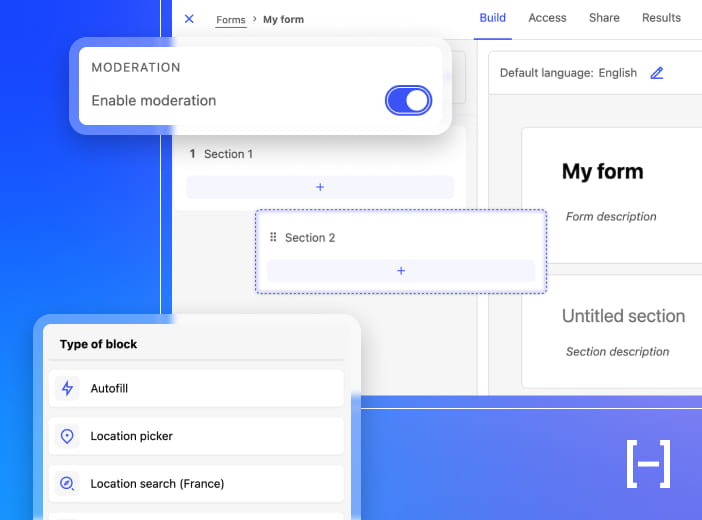
- Ready to use: easily accessible via intuitive interfaces and dedicated output ports (dashboard, API, visualizations, tabular views). The data is directly exploitable, with no technical dependencies
- Designed for scale: built for broad use across the organisation, it gains in value as it is adopted (80/20 logic)
- Business need-oriented: it addresses a clearly identified question or use case. Without a business purpose, there is no product
- Maintained over time: its quality and updates are ensured over the long term. Monitoring, continuous improvement and user feedback strengthen trust and usage
- Governed by a data contract: schema, quality, access, SLAs. The rules are explicit and shared, ensuring trust from all
What is the difference between a data product and a raw dataset?
The difference lies not in the data itself, but in how it is packaged:
| Criteria | Data product | Raw dataset |
|---|---|---|
| Identified owner | Always | Rarely |
| Business documentation | Integrated and maintained | Often absent |
| SLA/data contract | Yes | No |
| Accessible to non-technical users | Designed for this audience | Rarely |
| Reusable across domains | Yes – that is the objective | Difficult |
| Example use cases | Yes | Rarely |
What are the three key roles in the data product ecosystem?
The success of a data product relies on clarity of responsibilities. These three roles must coexist: without clearly defined ownership, quality degrades; without an active consumer, the investment is not justified; without an application layer, data remains difficult to exploit in everyday usage.
| Role | Mission |
|---|---|
| Data Product Owner | Responsible for the value delivered. Knows the business and the data. Prioritizes developments, champions the roadmap, and is accountable to consumers for quality. |
| Applications/AI | Systems fed by data products to create new concrete use cases, accelerate innovation or strengthen operational efficiency. |
| Business consumer | Teams (such as in finance, marketing, innovation, operations, or HR) that use the product to make decisions. Their feedback drives developments and their adoption justifies the investment. |
What is a data product marketplace for?
Creating a data product only makes full sense when producers meet users in a single space. It is critical to avoid the pitfall of just sharing products informally as this hinders adoption and collaboration. A data product marketplace acts as a strategic and engaging storefront into the organization’s data products. It brings three stakeholders together in the same space: consumers find what they need and can exploit data products without switching tools, producers see what is being used, and governance teams control access and quality. The difference from a simple data catalog is that every interaction is measurable, and every journey is optimizable.
65% of Data Voices believe organizations should implement an e-commerce style data marketplace in order to simplify and streamline access to data products across the entire organization. If we want data to be used, it must be presented like a product: with a catalog, seamless search, clear documentation, user reviews and simple consumption tools.
What are the best practices for high-impact data products?
1. Focus on packaging
A data product is not just about its content. Form matters as much as substance. A well-packaged product means:
- A clear product page: business name, description, use cases, visible owner
- A readable data contract: SLA, quality, schema, access
- An adapted interface: dashboard, API, export depending on use cases
With Huwise, package your data in your organization’s brand look and feel without having to write a single line of code.
2. Observe real adoption
Providing a data product without usage measurement is like launching a product without collecting feedback on its adoption. The most effective approach draws directly from e-commerce: rely on a conversion funnel specific to each data product, then analyze each step to identify friction points and moments where engagement drops. In practice, this means tracking the complete consumer journey, from discovering the product in the catalog to actual data consumption, and acting on each step.

Today, a Product Owner working on a digital journey may decide to deprioritize—or even remove—tracking capabilities due to time constraints. That is a cultural mistake. Data must not be seen as a byproduct, but as a strategic asset used to manage performance, drive continuous improvement, and support cross-functional business use cases.
| Funnel stage | What we measure and why |
|---|---|
| Discovery | Number of product page views in the catalog. Reveals the attractiveness of the title, description and packaging. A rarely viewed product is often poorly named or categorized. |
| Exploration | Time spent on the page, sections consulted, documentation downloads. Indicates whether the data contract and metadata are convincing enough for users to move forward and take the next step. |
| Access request | Number and profile of access requests. Strong signal of real demand that is cross-referenced with the approval rate to detect governance friction. |
| Consumption | API calls, dataset downloads, dashboard views. This is the real conversion: the data is being used. Tracking frequency distinguishes one-off usage from lasting integration into processes. |
| Reuse | The product is referenced in other data products (data lineage), integrated into AI models or recurring reports. Reuse is the ultimate signal of value created. |
3. Focus efforts on "best-sellers"
As on an e-commerce site, a small portion of data products generates the majority of usage. Identifying these strategic assets allows maintenance, communication and improvements to be concentrated where they have the most impact. The conversion funnel also reveals underperforming assets: improve their product page, reposition them in the catalog, or remove them to avoid noise.
With Huwise, measure and improve data usage with an integrated conversion funnel.
How does AI continuously improve data products?
The most advanced platforms no longer simply publish and manage data products: they integrate AI agents capable of acting on their lifecycle to continuously improve them. However, humans remain central to key decisions, guaranteeing quality and trust.
The data product is not just a service provided to humans: it is also indispensable to drive reliable and effective AI.
At Huwise, this trend has led us to create three AI agents that leverage the intelligence and usage statistics captured by the marketplace:
- Marketplace Curator: continuously analyzes usage (clicks, consumption, drop-offs) and suggests actions to improve the adoption of each data product
- Opportunity Spotter: identifies gaps in the catalog and the data products with the highest value potential, then helps prioritize them
- Data Product Builder: supports the creation of new data products, from defining the need through to packaging
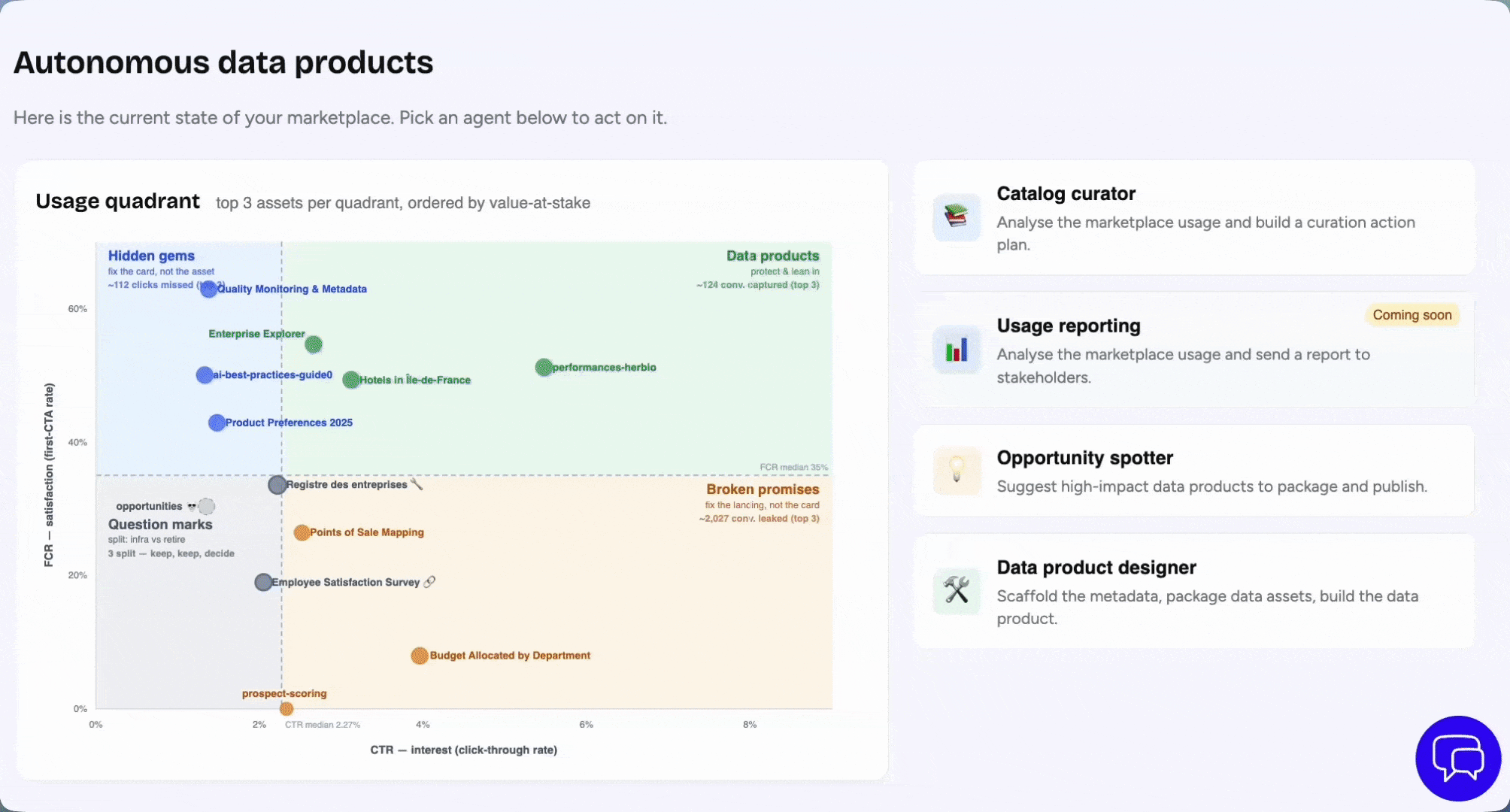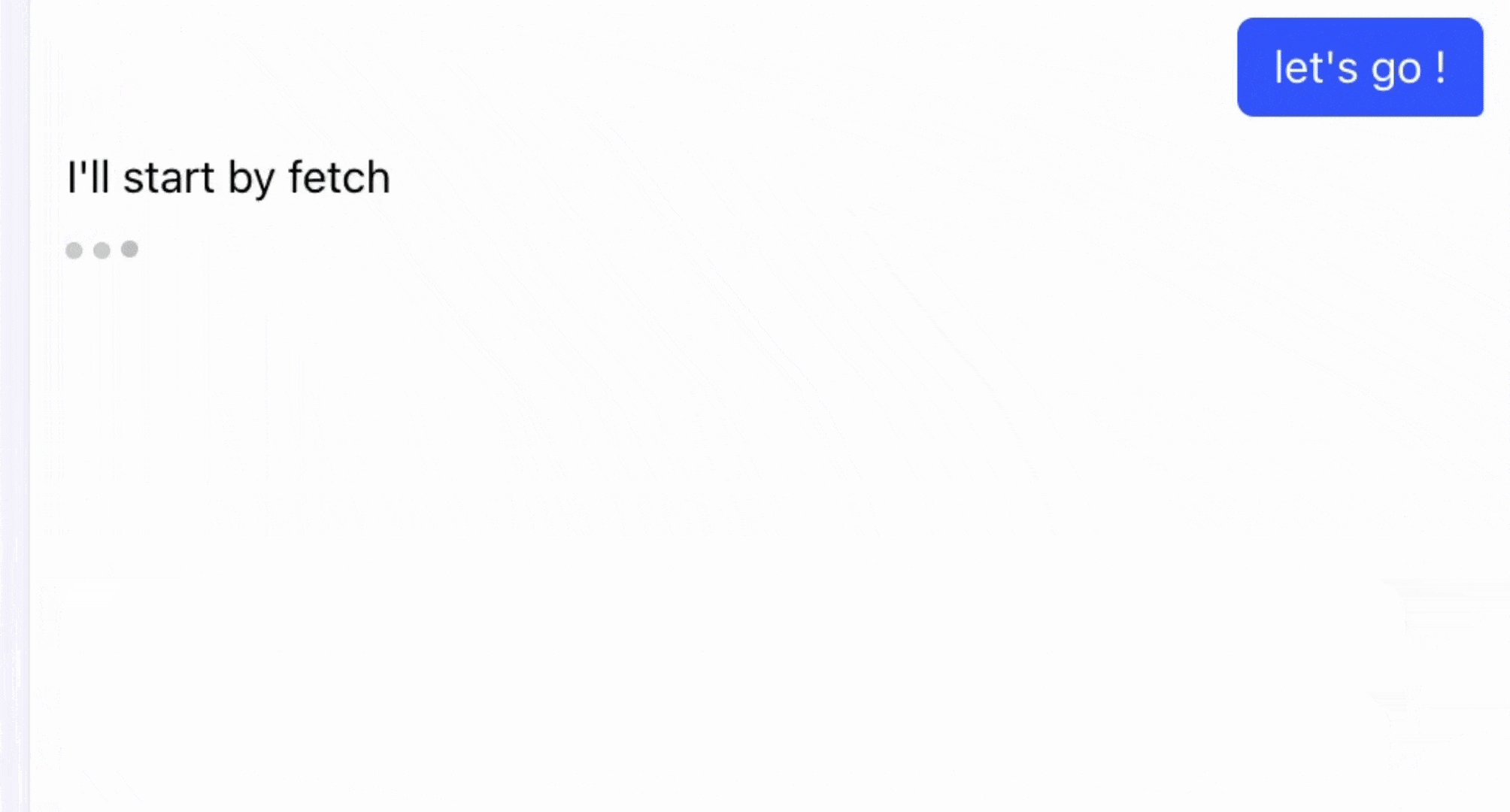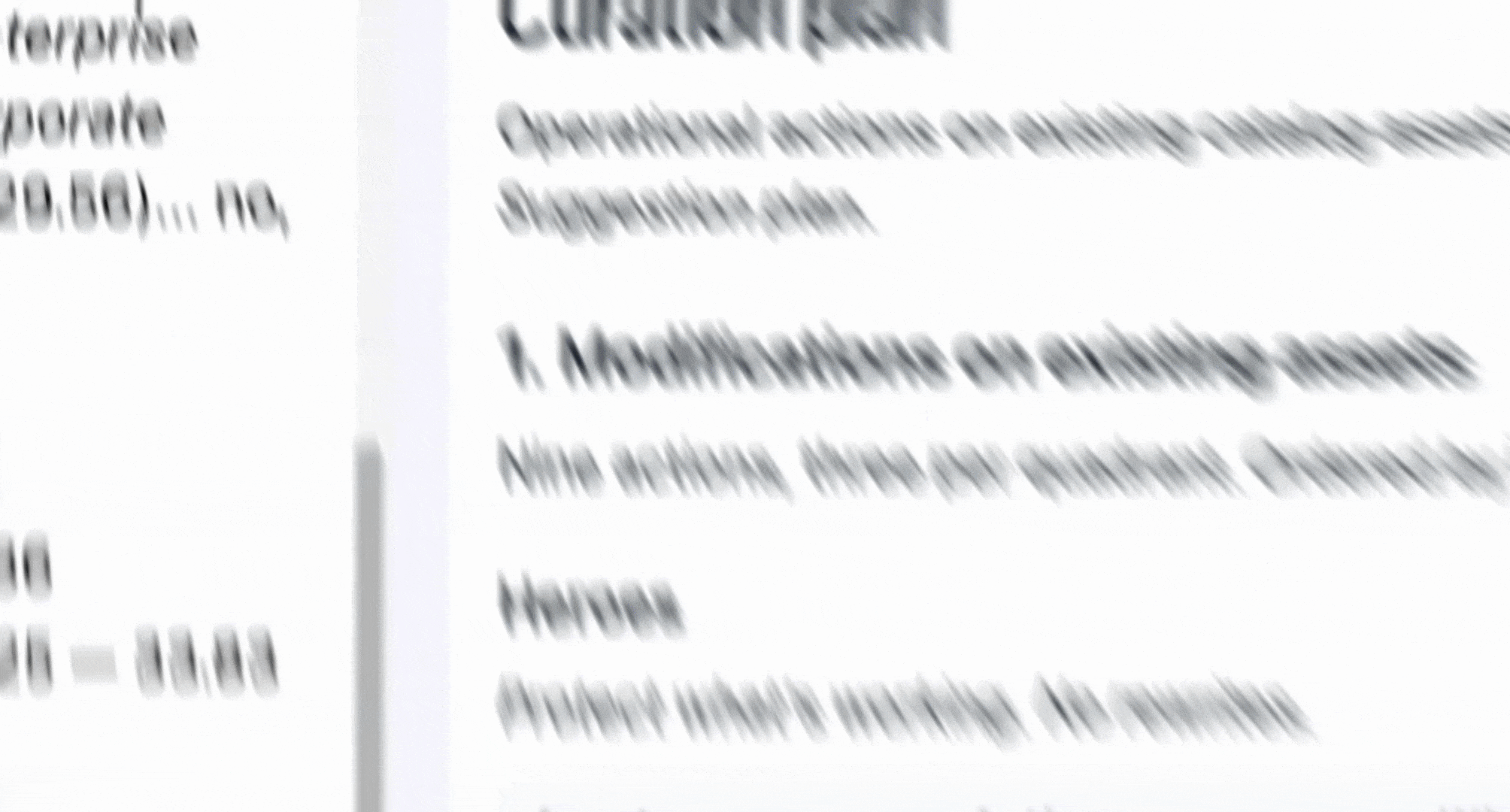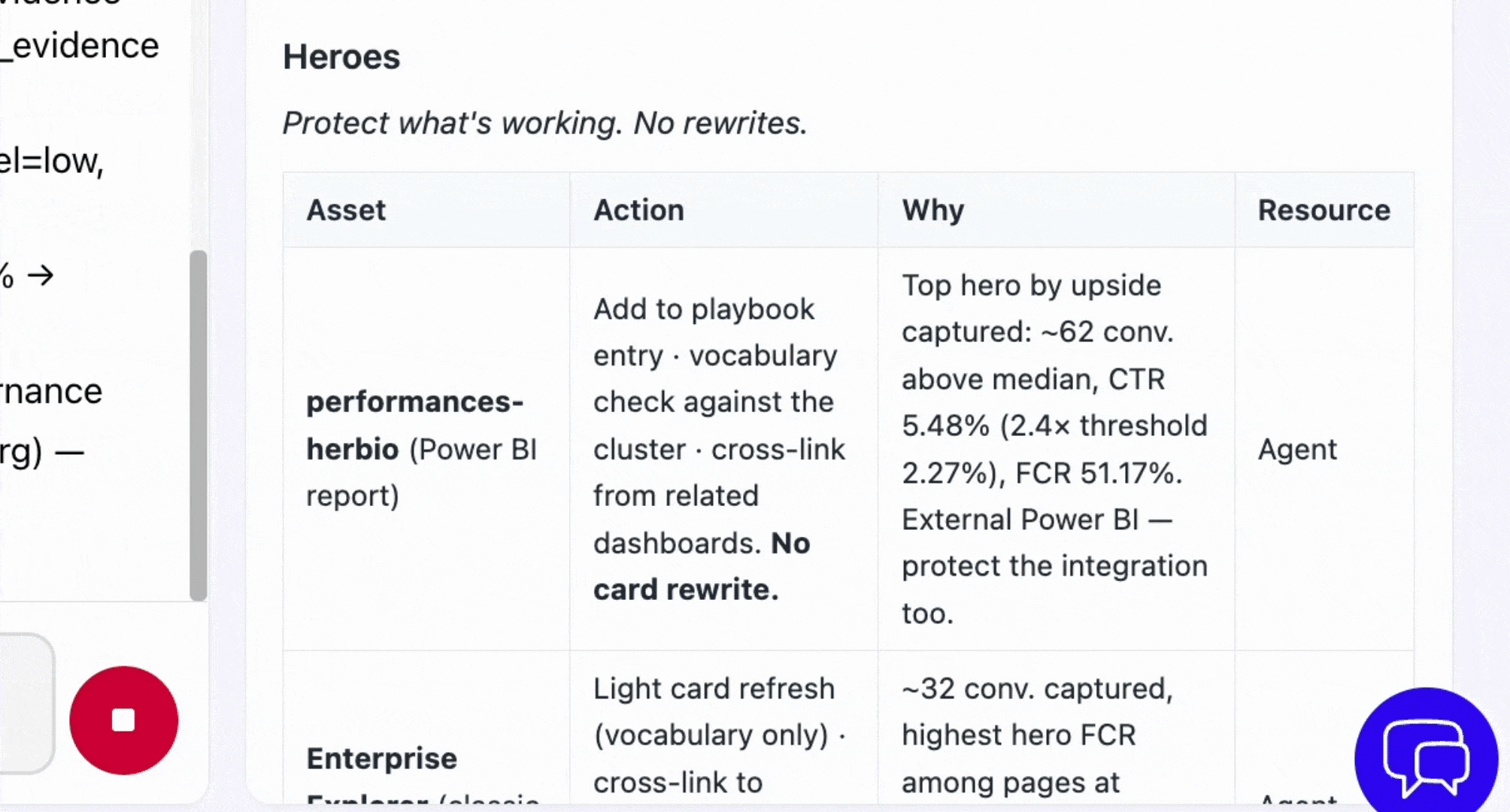
This is the logical continuation of the Pareto 80/20 law applied to data: rather than waiting for a human to identify the 20% of products that create value, agents detect them in real time and act directly in the data product marketplace, subject to validation by the data product owner or administrator.
Making data a product is not simply about making it available - value only comes from usage
Data products are not yet another data concept to add to your already busy roadmap. They are the answer to the issue that most organizations suffer from – data exists but is simply not used enough.
This is precisely Huwise’s mission: to help you transform your data into exploitable data products, make them accessible at scale and maximize their impact through a data product marketplace designed to drive usage and consumption.
If you’d like to learn more about data products, request a demo.
FAQ — Frequently asked questions about data products
-
A dataset is a collection of raw data, often without a clear owner or structured documentation. A data product is a dataset packaged as a product: with efforts made to present it attractively, an identified owner, defined SLAs, maintained documentation and measurement of usage. The difference is strategic, not technical.
-
The data product owner. They understand both the business and the data, meaning they can promote it in the best possible way, prioritize product developments and are accountable for its quality to consumers. Without an identified owner, there is no data product — just a dataset.
-
A data contract is a set of explicit, shared rules governing a data product: data schema, expected quality levels, access conditions and SLAs. It formalizes the producer’s commitment to consumers and is indispensable to building long-term trust.
-
No — quite the opposite. One of the defining differences of a data product compared to a data asset is precisely that it is accessible to non-technical employees, via intuitive interfaces (dashboards, prepared views, exports). It is designed for broad usage. If only a data team can use it, it is still a dataset.
-
A catalog lists data. A data product marketplace showcases it, measures its adoption and optimizes its distribution — just like an e-commerce site. Every interaction is traceable, and every consumer journey is optimizable. It is this usage logic that distinguishes the two approaches.
Share this post:
Articles on the same topic:
About the author

Flore Brame accompagne le développement et la mise en valeur de la solution Huwise en tant que Product Marketing Manager. En s’appuyant sur des retours terrain et des cas d’usage, elle met en perspective la valeur de ces innovations et montre comment elles accélérent l’usage des données à l’échelle de l’organisation, pour tous les profils – des experts aux utilisateurs en découverte.
More articles